ScrapydWeb:用于 Scrapyd 集群管理的 web 应用,支持 Scrapy 日志分析和可视化
环境依赖 Python 3.7
# 安装scrapyd
pip install scrapyd
# 安装scrapydweb
pip install scrapydweb
启动 ScrapydWeb
# 通过命令行启动 scrapyd
scrapyd
# 通过命令行启动 scrapydweb
scrapydweb
启动 scrapyweb 后在当前目录生产配置文件
scrapydweb_settings_v10.py
ScrapydWeb 配置修改
- 请先确保所有主机都已经安装和启动 Scrapyd,如果需要远程访问 Scrapyd,则需将 Scrapyd 配置文件中的 bind_address 修改为 bind_address = 0.0.0.0,然后重启 Scrapyd service。
- 开发主机或任一台主机安装 ScrapydWeb:pip install scrapydweb
- 通过运行命令 scrapydweb 启动 ScrapydWeb(首次启动将自动在当前工作目录生成配置文件)。
- 启用 HTTP 基本认证(可选):
ENABLE_AUTH = True
USERNAME = 'username'
PASSWORD = 'password'
- 添加 Scrapyd server,支持字符串和元组两种配置格式,支持添加认证信息和分组/标签:
SCRAPYD_SERVERS = [
'127.0.0.1',
# 'username:password@localhost:6801#group',
('username', 'password', 'localhost', '6801', 'group'),
]
- 运行命令 scrapydweb 重启 ScrapydWeb。
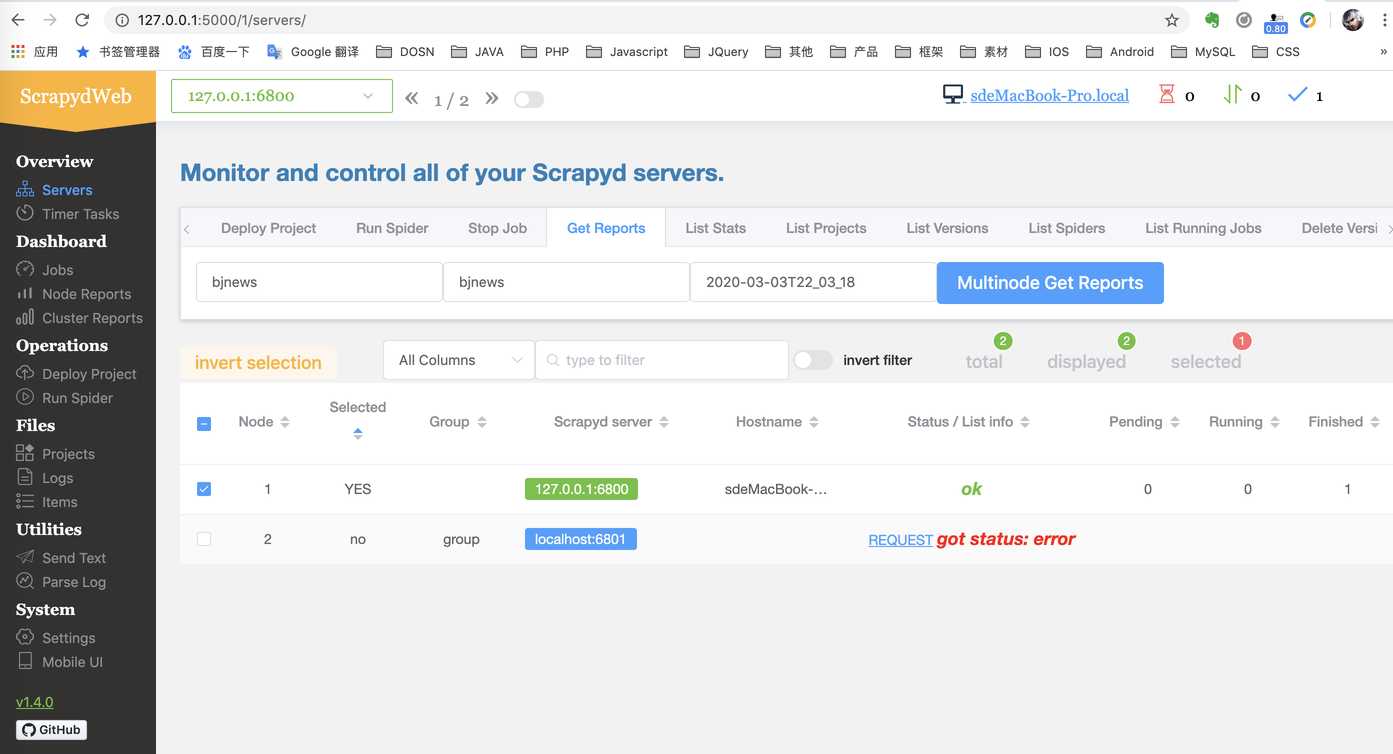
运行效果
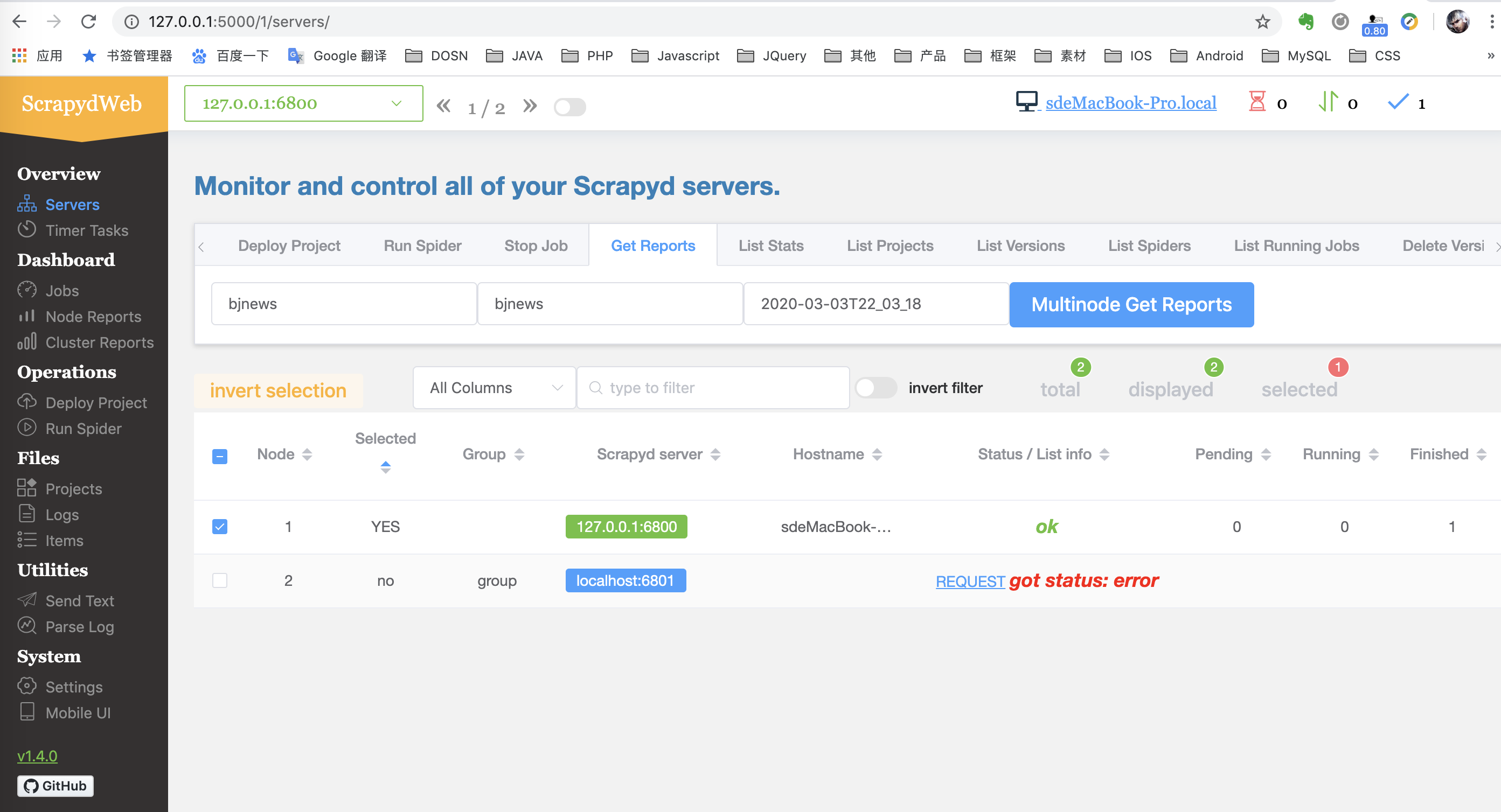
- 上传并运行 Scrapy 爬虫,将已经写好到 Scrapy 爬虫代码压缩成 zip 上传并部署
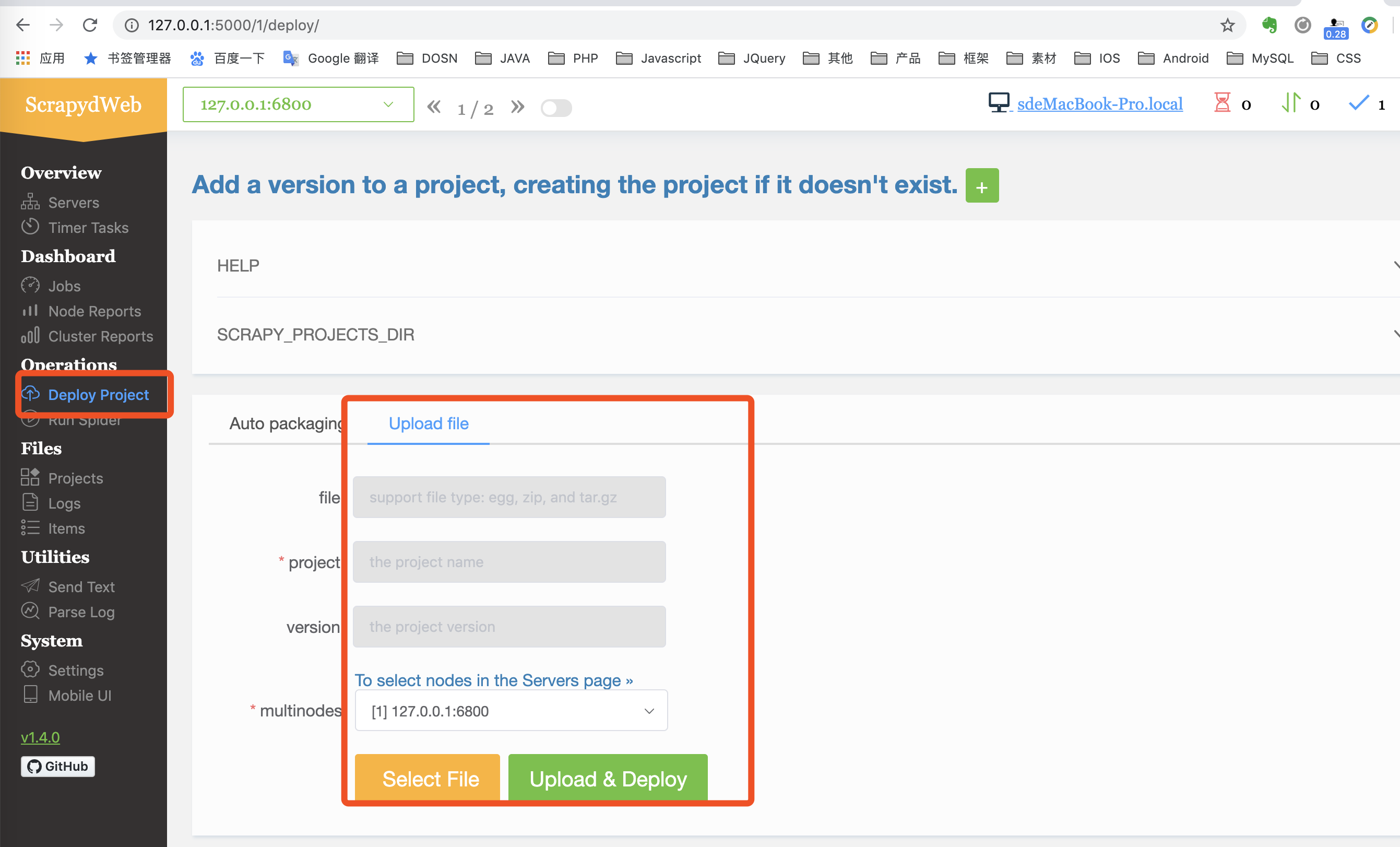
- 点击 start 启动任务
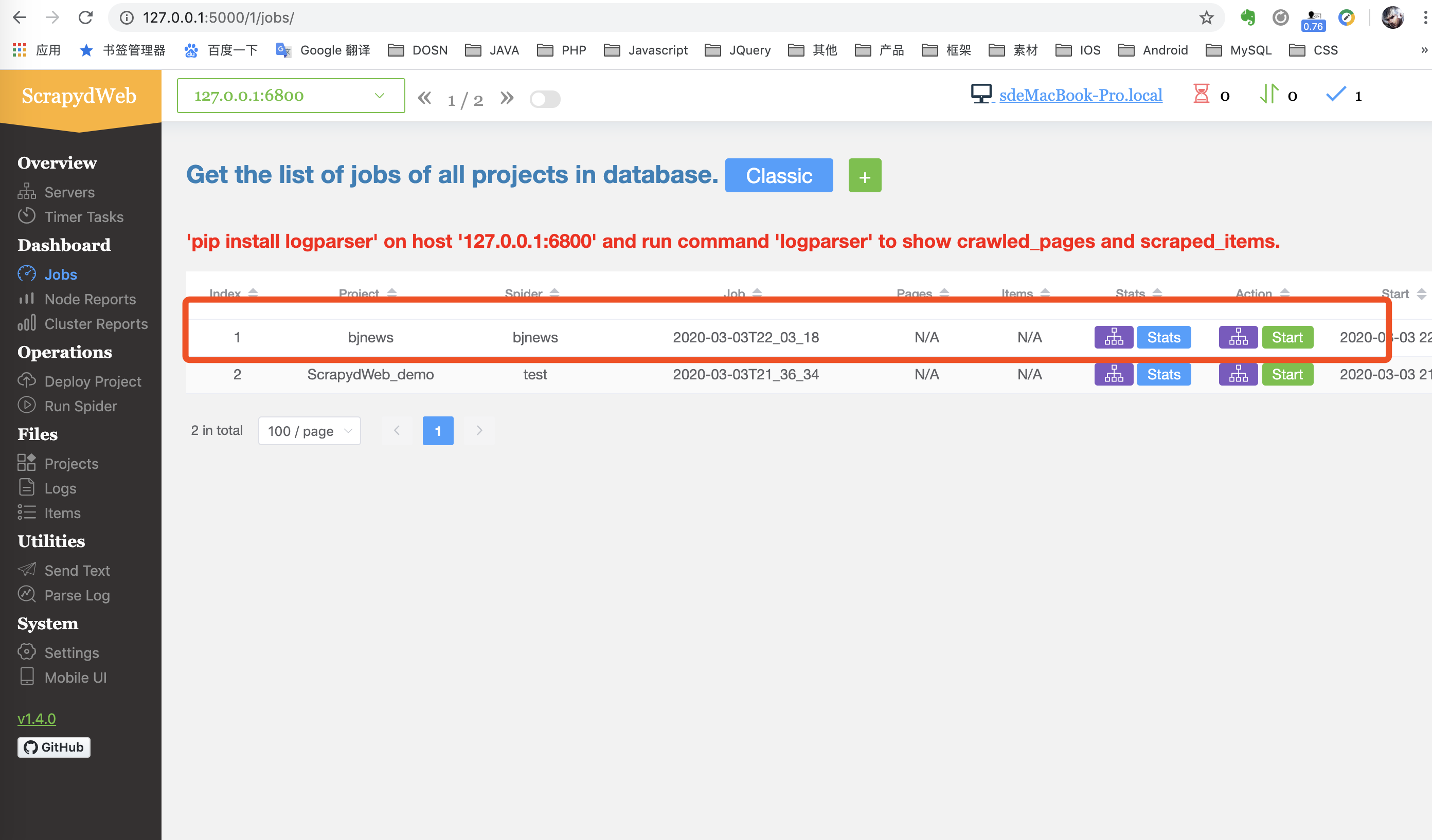
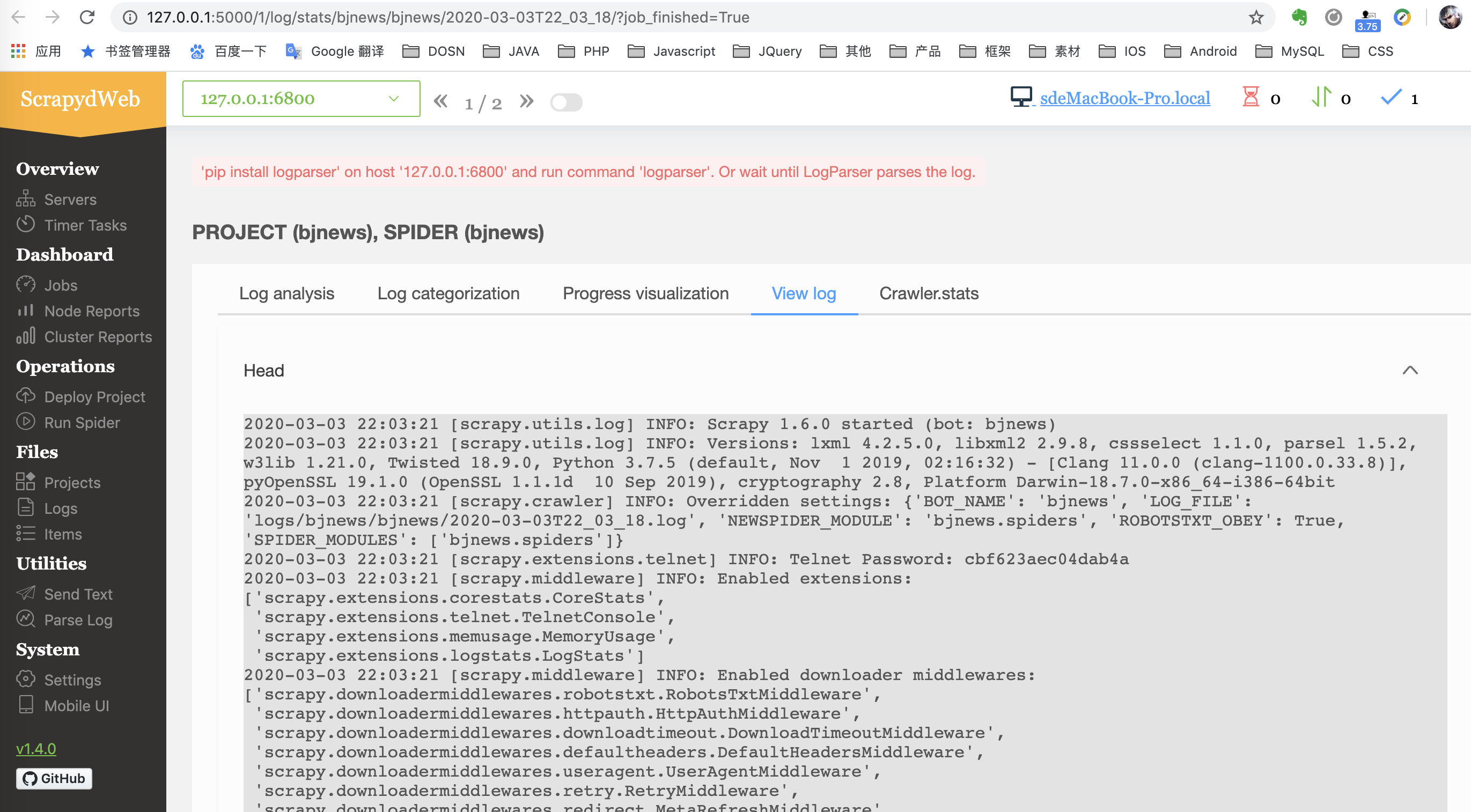
- 启动后查看日志
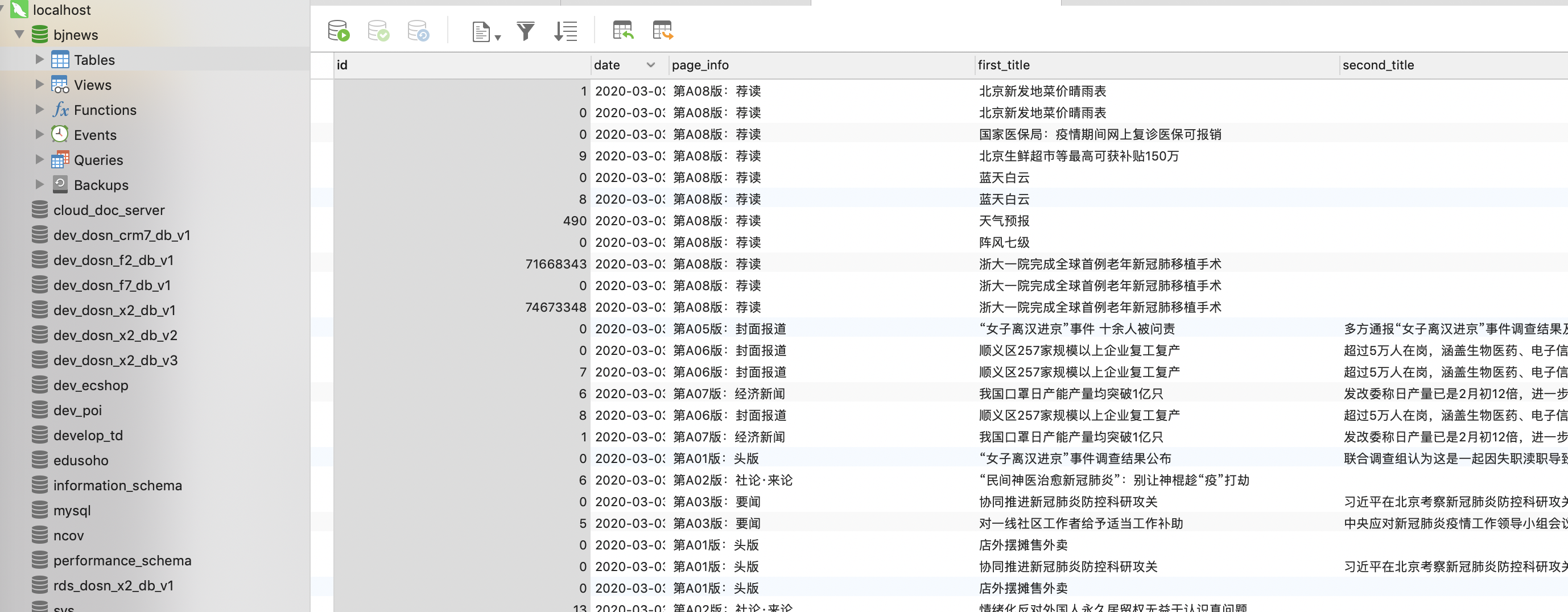
- 查看数据库中爬取的数据
注意部署过程中的坑!!!
1. 执行 Job 出现报错 builtins.AttributeError: ‘int’ object has no attribute ‘splitlines’
问题原因:包版本兼容问题
解决方法:版本回退
pip install Twisted==18.9.0
pip install redis==3.0.1
pip install Scrapy==1.6.0
2. 查看 log 出现报错 ‘pip install logparser’ on host ‘127.0.0.1:6800’ and run command ‘logparser’. Or wait until LogParser parses the log.
问题原因:logparser包没有安装和启动
解决方法:安装 logparser 包并启动
# 安装
pip install logparser
# 启动
logparser
参考源码
https://github.com/scrapy/scrapy
https://github.com/my8100/scrapyd
https://github.com/my8100/scrapydweb
https://github.com/my8100/logparser